Command Query Responsibility Segregation represents a fundamental shift in how we think about data persistence and retrieval in distributed systems. Rather than treating reads and writes as symmetric operations against a single data model, CQRS acknowledges the inherent differences between these operations and optimizes each path independently. In the context of AWS services, this pattern becomes particularly powerful when we leverage the managed services ecosystem to handle the complexity of maintaining separate command and query models.
Event sourcing fundamentally changes how applications handle state management by storing every state change as an immutable event rather than maintaining current state snapshots. This architectural pattern becomes particularly powerful when implemented on AWS, where managed services provide the scalability and durability required for enterprise-grade event sourcing systems. Understanding how to leverage AWS services effectively for event sourcing can transform application architectures from brittle state-dependent systems into resilient, audit-friendly, and highly scalable solutions.
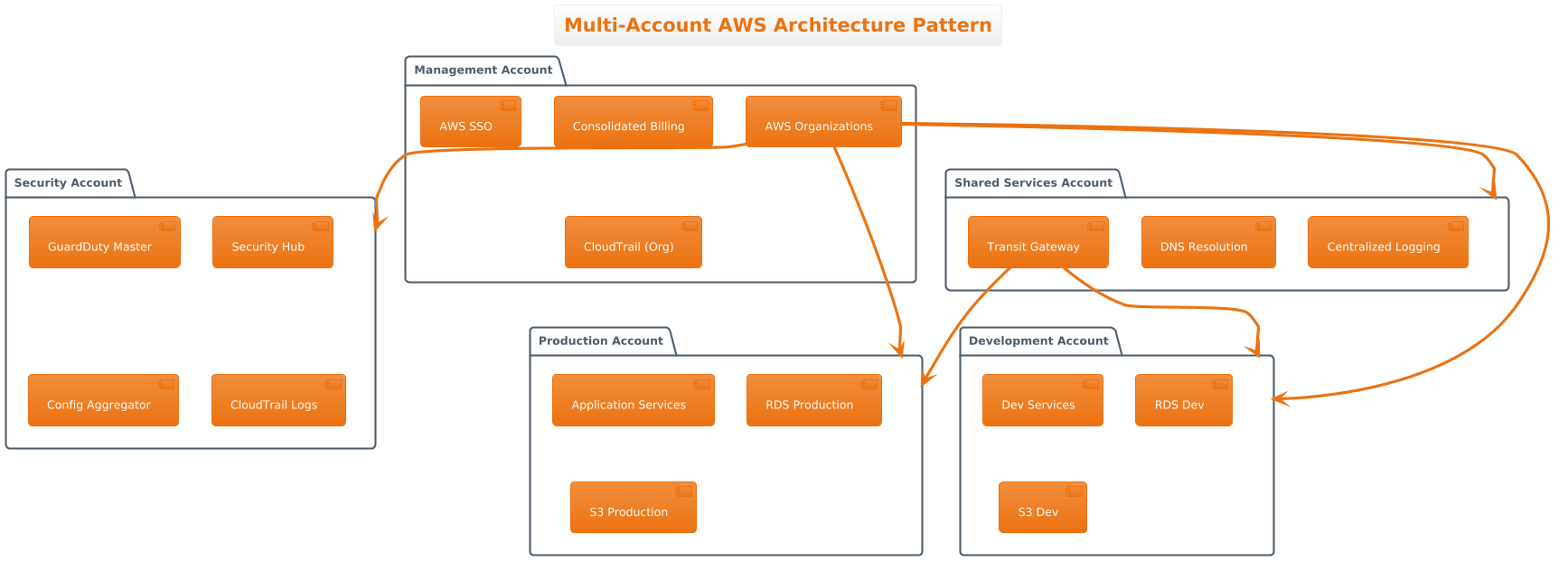
Enterprise organizations face unique challenges when scaling their AWS infrastructure beyond simple single-account deployments. As applications grow in complexity and regulatory requirements become more stringent, the need for sophisticated multi-account strategies becomes paramount. This exploration delves into proven patterns that enable organizations to maintain security, compliance, and operational efficiency across distributed cloud environments.
Understanding the Multi-Account Imperative
The traditional approach of housing all resources within a single AWS account quickly becomes untenable for enterprise applications. Security boundaries blur when development, staging, and production workloads share the same account, creating unnecessary risk exposure. Compliance frameworks often mandate strict separation of environments, making single-account architectures insufficient for regulated industries.
The ephemeral nature of containers and serverless functions introduces unique security challenges that traditional application security models weren’t designed to address. Unlike long-running virtual machines or physical servers, these workloads exist for minutes, hours, or even seconds, making traditional security monitoring and patching strategies ineffective. This fundamental shift requires a new approach to security that embraces the transient nature of these workloads while maintaining robust protection against evolving threats.
Container and serverless security operates on the principle that protection must be built into the deployment pipeline rather than applied after deployment. This shift-left approach ensures that security controls are embedded throughout the development lifecycle, from image creation to runtime execution. The challenge lies in balancing security rigor with the speed and agility that containerized and serverless architectures promise to deliver.
The proliferation of microservices and distributed architectures has dramatically increased the complexity of managing sensitive information in cloud-native applications. Database credentials, API keys, encryption keys, and other secrets must be securely stored, distributed, and rotated across potentially hundreds of services and environments. Traditional approaches of hardcoding secrets or storing them in configuration files are not only insecure but fundamentally incompatible with the dynamic nature of cloud-native deployments.
Modern secrets management requires a comprehensive strategy that addresses the entire lifecycle of sensitive information, from generation and distribution to rotation and revocation. This strategy must account for the ephemeral nature of cloud-native workloads, the need for automated operations, and the security requirements of handling sensitive data across network boundaries.
Modern cloud-native applications face unprecedented challenges in managing user identities and controlling access to resources. The traditional perimeter-based security model has given way to sophisticated identity and access management (IAM) patterns that embrace the distributed nature of cloud architectures. Understanding these patterns is crucial for building secure, scalable applications that can adapt to evolving security requirements while maintaining excellent user experiences.
The Evolution of Identity Management
Cloud-native applications operate in environments where traditional network boundaries have dissolved. Users access applications from various devices and locations, while applications themselves consist of numerous microservices communicating across network boundaries. This distributed architecture demands identity management solutions that can provide consistent security policies across all components while maintaining the flexibility needed for modern development practices.
The traditional security model of “trust but verify” has become fundamentally inadequate for modern cloud-native environments. Zero-trust architecture operates on the principle that no entity—whether inside or outside the network perimeter—should be trusted by default. This paradigm shift represents a critical evolution in how we approach security design, particularly as organizations embrace distributed architectures, remote workforces, and multi-cloud strategies.
In cloud-native applications, the concept of a network perimeter has largely dissolved. Services communicate across various networks, containers spin up and down dynamically, and data flows through multiple layers of infrastructure. Zero-trust provides a framework for securing these complex, distributed systems by treating every access request as potentially hostile and requiring explicit verification before granting access to any resource.